第8章:降维分析
### 数据准备 ###
# 清空工作空间
rm(list = ls())案例引入
NBA,全称为美国职业篮球联赛(National Basketball Association),作为美国四大职业体育联盟之一,在美国本土,在四大联赛中的排名绝非第一;而就全球而言,尤其是中国,其普及率和收看率,则是远远高于其他三大联盟。
NBA作为商业联盟,不管是联盟还是球队,最关心的问题还是盈利,其球队市值估价也逐年提高。据《福布斯》2019年发布的NBA球队市值,30支NBA球队的估值首次全部达到或超过12亿美元,平均市值为19亿美元,较去年增长13%,是三年前的3倍,其中,纽约尼克斯达到40亿美金,是所有球队中最高的。对于NBA球队来说,其收入包括门票收入、广告收入等,而球队支出中,则有一大部分在于球员薪金。
那么,自由球员在自由市场中的价值,具体表现为其下一份合同的薪金大小,是由哪些因素决定的?根据经验,主要的因素应该包括其在球场上的表现以及其展现的天赋和能力,再或者是对胜利的贡献。对于球队经理来说,需要主观地综合考虑多方面的因素,给出合适的合同。因此对球员薪金影响因素的量化分析,可以更合理地估计出球员在各个方面的水平与价值,对应合理的薪金合同,也有助于球队挑选更具性价比的球员,组建更为合理的阵容。这对球队战绩的提升、球队运营收入的增益,有着重要的意义。
本章案例数据收集自截至2019年NBA球员季后赛总得分和每个球员的比赛详细数据。该数据收集了2448条NBA职业篮球运动员的各项比赛数据,其中包含勒布朗·詹姆斯、迈克尔·乔丹、科比·布莱恩特等多位全能巨星球员的投篮、三分球、罚球、助攻、抢断次数和季后赛总得分等18个变量信息。变量说明表如下所示:
| 变量类型 | 变量名 | 详细说明 | 取值范围 | |
|---|---|---|---|---|
| 因变量 | 生涯总得分 | 连续变量 | 0-6911 | |
| 自变量 | 个人信息 | 球员 | 文本数据 | 每个球员的官方姓名 |
| 出勤统计 | 出场数 | 连续变量 | 1-259 | |
| 上场总时间 | 连续变量 | 0-10059 | ||
| 投篮统计 | 投篮率 | 连续变量 | 0%-100% | |
| 命中次数 | 连续变量 | 0-2457 | ||
| 出手次数 | 连续变量 | 0-5006 | ||
| 三分统计 | 三分投球率 | 连续变量 | 0%-100% | |
| 三分命中次数 | 连续变量 | 0-410 | ||
| 三分出手次数 | 连续变量 | 0-1116 | ||
| 罚球统计 | 罚球率 | 连续变量 | 0%-100% | |
| 罚球命中次数 | 连续变量 | 0-1627 | ||
| 罚球出手次数 | 连续变量 | 0-2317 | ||
| 其他技术统计 | 篮板数 | 连续变量 | 0-4104 | |
| 助攻次数 | 连续变量 | 0-2346 | ||
| 抢断次数 | 连续变量 | 0-419 | ||
| 盖帽次数 | 连续变量 | 0-568 | ||
| 失误次数 | 连续变量 | 0-866 | ||
| 犯规次数 | 连续变量 | 0-797 |
8.1 主成分分析
读入数据并绘制相关系数矩阵
读入数据NBA.xlsx,命名为nba,并将第2-18个变量提取为一个新的数据框,命名为predictor。绘制变量之间的相关系数矩阵图
library(psych)
library(readxl)
nba <- read_excel("./data/NBA.xlsx")
predictor <- nba[2:18]
## 变量间相关系数
M <- cor(predictor)par(family='STHeiti')
corrplot::corrplot(M, tl.srt = 60,tl.col = "black")

根据变量的相关系数图可以看出,部分变量之间的正相关性较强,例如出场数和上场总时间,命中次数和出手次数等。
选择主成分个数
使用psych包中的scree()函数,绘制崖底碎石土,选择合适的主成分个数。scree()函数中,通过指定参数factors和pc的取值,生成主成分分析或因子分析的崖底碎石图,hline参数取值为绘制水平直线的高度,默认值为1,设置为负数则不绘制水平线。scree()函数会返回根据特征值绘制的崖底碎石图,同时返回特征值向量,因此可以使用该返回值计算累计方差贡献率。
## 主成分分析选择因子数目
par(family='STHeiti')
result1 <- scree(predictor, factors = F, pc = T, main = "主成分分析崖底碎石图", hline = -1)

## 计算累计方差贡献率
cumvar <- round(cumsum(result1$pcv)/sum(result1$pcv),2)
cat('前三个主成分累计方差贡献率为:', cumvar[1:3])## 前三个主成分累计方差贡献率为: 0.63 0.73 0.8根据崖底碎石图的拐点,结合主成分解释总体方差的比例(约为80%),选择主成分个数为3。
提取主成分与结果解读
根据任务二中确定的主成分个数,提取主成分,并对结果进行解读。
## 提取主成分
pc <- principal(predictor, nfactors = 3)
pc## Principal Components Analysis
## Call: principal(r = predictor, nfactors = 3)
## Standardized loadings (pattern matrix) based upon correlation matrix
## RC1 RC2 RC3 h2 u2 com
## 出场数 0.85 0.30 0.20 0.86 0.144 1.4
## 上场总时间(min) 0.91 0.33 0.13 0.95 0.051 1.3
## 投篮率 0.12 -0.07 0.80 0.67 0.334 1.1
## 命中次数 0.93 0.25 0.08 0.94 0.059 1.2
## 出手次数 0.92 0.28 0.08 0.93 0.065 1.2
## 三分投球率 -0.09 0.54 0.51 0.57 0.432 2.0
## 三分命中次数 0.31 0.90 0.03 0.91 0.087 1.2
## 三分出手次数 0.33 0.90 0.03 0.93 0.071 1.3
## 罚球率 0.17 0.11 0.61 0.41 0.591 1.2
## 罚球命中次数 0.92 0.23 0.05 0.90 0.101 1.1
## 罚球出手次数 0.94 0.17 0.05 0.92 0.084 1.1
## 篮板数 0.90 0.01 0.11 0.83 0.174 1.0
## 助攻次数 0.77 0.41 0.03 0.76 0.238 1.5
## 抢断次数 0.70 0.56 0.08 0.81 0.191 1.9
## 盖帽次数 0.71 0.02 0.13 0.53 0.475 1.1
## 失误次数 0.73 0.52 0.08 0.80 0.195 1.8
## 犯规次数 0.91 0.18 0.16 0.88 0.120 1.1
##
## RC1 RC2 RC3
## SS loadings 9.00 3.16 1.43
## Proportion Var 0.53 0.19 0.08
## Cumulative Var 0.53 0.72 0.80
## Proportion Explained 0.66 0.23 0.10
## Cumulative Proportion 0.66 0.90 1.00
##
## Mean item complexity = 1.3
## Test of the hypothesis that 3 components are sufficient.
##
## The root mean square of the residuals (RMSR) is 0.05
## with the empirical chi square 1937.64 with prob < 0
##
## Fit based upon off diagonal values = 0.99R的输出结果中,前三列为三个成分的载荷,它是指观测变量与主成分的相关系数,这里需要注意,载荷系数的正负本身没有意义 ,但是不同载荷系数之间的正负对比是有意义的;h2栏指主成分对每个原始变量的方差贡献率,即主成分对每个变量的方差解释度,由每个主成分的载荷平方求和得到,例如对于出场数,三个主成分一共解释了86%的方差;u2栏指成分唯一性,由1-h2计算得到,即方差无法被主成分解释的比例;最后一列com为主成分在每个变量上的Hoffman’s复杂度指数,\(X_i\)对应的复杂度由\(\frac{\left(\Sigma_{k} \rho_{k i}^{2}\right)^{2}}{\Sigma_{k}\left(\rho_{k i}\right)^{4}}\)计算得到,其中\(\rho_{k i}\)为第k个主成分与变量\(X_i\)的因子载荷,该指数表示前k个主成分与第i个变量之间的综合相关性大小,值越大表示整体相关性越强。
从代码结果的最后一个输出表可以看出,第一主成分解释了出场数85%的方差,第三主成分解释了投篮率80%的方差,第二主成分则分别解释了三分命中次数和三分出手次数90%的方差。代码结果中的累计贡献率显示,前三个主成分的累计贡献率达到了80%,因此使用这三个主成分可以很好地概括这组数据。
利用主成分分量的值可以对各个主成分进行解释,第一主成分的三分投球率分量为负值,其余都为正值,除了投篮率、罚球率、三分投球率、三分命中次数等表示“命中”占比的指标外,其余分量大多数都大于0.5,因此第一主成分反映球员的比赛活跃与主动程度,可以称为场内活跃因子。第二大主成分在三分球的命中次数和出手次数上分量高达90%,在2010-2018的8个NBA赛季中,球员的三分球得分尝试大幅度增加,因为球队都不约而同地得出了一个结论:根据加入胜率的计算,三分球投篮尝试(特别是从角落投出)在统计数据上让球队赢得比赛的可能性增加20%到35%。因此,我们可以称第二大主成分为胜率加成因子。第三大主成分在投篮(命中)率、罚球(命中)率和三分投球(命中)率分量较大,由于命中率体现了球员的篮球技术水平,第三主成分则可以被称为技术水平因子。
计算主成分得分
通过principal()函数返回的weights对象,可以得到每个变量的主成分得分系数,从而将主成分表示为变量的线性组合形式。在principal()函数的基础上,添加参数score = TRUE,即可以获得所有球员样本在三个主成分上的得分,通过这个得分,可以从三个角度(场内活跃因子、胜率加成因子、技术水平因子)对球员的综合实力进行评价。请计算主成分得分系数,并输出前六个样本的主成分得分,对结果进行适当解读。
round(unclass(pc$weights), 2) # 计算主成分得分系数## RC1 RC2 RC3
## 出场数 0.09 -0.01 0.07
## 上场总时间(min) 0.10 0.00 0.01
## 投篮率 -0.02 -0.13 0.64
## 命中次数 0.12 -0.04 -0.02
## 出手次数 0.11 -0.02 -0.03
## 三分投球率 -0.15 0.25 0.37
## 三分命中次数 -0.10 0.41 -0.08
## 三分出手次数 -0.10 0.40 -0.08
## 罚球率 -0.03 -0.02 0.46
## 罚球命中次数 0.12 -0.05 -0.05
## 罚球出手次数 0.14 -0.08 -0.04
## 篮板数 0.15 -0.16 0.02
## 助攻次数 0.07 0.08 -0.07
## 抢断次数 0.02 0.16 -0.04
## 盖帽次数 0.12 -0.12 0.05
## 失误次数 0.04 0.13 -0.04
## 犯规次数 0.12 -0.08 0.05## 计算主成分得分
pc <- principal(predictor, nfactors = 3, scores = TRUE)
head(pc$scores)## RC1 RC2 RC3
## [1,] 8.303699 8.511875 -2.74635320
## [2,] 7.180972 3.157658 -1.17880314
## [3,] 7.867405 -3.731918 0.03163649
## [4,] 6.281025 6.742762 -1.80571153
## [5,] 10.055778 -4.066821 -0.12789204
## [6,] 10.340703 -3.711050 0.36334196利用如下公式可得到主成分得分,以第一主成分为例:
\(PC_1\)=0.09 * 出场数 + 0.1 * 上场总时间-0.02 * 投篮率 + 0.12 * 命中次数 + 0.11 * 出手次数-0.15 * 三分投球率-0.1 * 三分命中次数-0.1 * 三分出手次数-0.03 * 罚球率 + 0.12 * 罚球命中次数 + 0.14 * 罚球出手次数 + 0.15 * 篮板数 + 0.07 * 助攻次数 + 0.02 * 抢断次数 + 0.12 * 盖帽次数 + 0.04 * 失误次数 + 0.12 * 犯规次数
以第一个球员为例,他的场内活跃因子和胜率加成因子得分较高,说明他是一位在比赛场上主动进攻类型的球员,但是他的技术水平因子得分较低,因此还是需要多加练习,提高自己的投篮命中率,从而获得更多分数。
8.2 因子分析
选择合适的公共因子数目
在进行因子分析之前,需要对数据进行标准化,再计算协方差矩阵;或等价地,使用原始数据的相关系数矩阵作为因子分析函数的输入。利用scree()函数绘制因子分析的崖底碎石图,结合累计方差贡献率(由fa()函数输出)等指标,选择合适的公因子数目。
## 因子分析
cov <- cov(nba[,2:18])
## 转换为相关系数矩阵(等价于标准化后数据的协方差矩阵)
cor <- cov2cor(cov)## 选择因子数目
par(family='STHeiti')
result2 <- scree(cor, factors = T, pc = F, main="因子分析崖底碎石图", hline = -1)

利用scree()函数绘制因子分析的崖底碎石图,结合累计方差贡献率(由fa()函数输出)等指标,设置公因子数为3。
提取公共因子
使用NBA季后赛球员数据来进行公共因子的提取,公因子数目根据任务五的结果所得。使用最大似然法提取未旋转的因子,对提取公共因子的结果进行解读。
## 提取公共因子
fa(cor, n.obs = 2448, nfactors = 3, rotate = "none", fm = "ml")## Factor Analysis using method = ml
## Call: fa(r = cor, nfactors = 3, n.obs = 2448, rotate = "none", fm = "ml")
## Standardized loadings (pattern matrix) based upon correlation matrix
## ML1 ML2 ML3 h2 u2 com
## 出场数 0.81 0.31 0.38 0.903 0.0970 1.7
## 上场总时间(min) 0.87 0.35 0.31 0.977 0.0228 1.6
## 投篮率 0.12 0.10 0.15 0.046 0.9537 2.7
## 命中次数 0.86 0.47 0.07 0.964 0.0359 1.6
## 出手次数 0.88 0.44 0.06 0.964 0.0365 1.5
## 三分投球率 0.27 -0.26 0.08 0.148 0.8521 2.1
## 三分命中次数 0.87 -0.49 -0.01 0.993 0.0074 1.6
## 三分出手次数 0.88 -0.47 -0.01 0.995 0.0048 1.5
## 罚球率 0.25 0.05 0.10 0.074 0.9258 1.4
## 罚球命中次数 0.85 0.51 -0.12 0.993 0.0066 1.7
## 罚球出手次数 0.82 0.55 -0.08 0.985 0.0154 1.8
## 篮板数 0.67 0.53 0.29 0.812 0.1879 2.3
## 助攻次数 0.80 0.28 0.07 0.729 0.2715 1.3
## 抢断次数 0.83 0.07 0.19 0.735 0.2650 1.1
## 盖帽次数 0.51 0.37 0.24 0.454 0.5462 2.3
## 失误次数 0.84 0.14 0.08 0.726 0.2738 1.1
## 犯规次数 0.78 0.43 0.34 0.902 0.0980 2.0
##
## ML1 ML2 ML3
## SS loadings 9.34 2.44 0.62
## Proportion Var 0.55 0.14 0.04
## Cumulative Var 0.55 0.69 0.73
## Proportion Explained 0.75 0.20 0.05
## Cumulative Proportion 0.75 0.95 1.00
##
## Mean item complexity = 1.7
## Test of the hypothesis that 3 factors are sufficient.
##
## The degrees of freedom for the null model are 136 and the objective function was 32.07 with Chi Square of 78273.06
## The degrees of freedom for the model are 88 and the objective function was 4.81
##
## The root mean square of the residuals (RMSR) is 0.04
## The df corrected root mean square of the residuals is 0.05
##
## The harmonic number of observations is 2448 with the empirical chi square 1017.8 with prob < 4.3e-158
## The total number of observations was 2448 with Likelihood Chi Square = 11717.56 with prob < 0
##
## Tucker Lewis Index of factoring reliability = 0.77
## RMSEA index = 0.232 and the 90 % confidence intervals are 0.229 0.236
## BIC = 11030.9
## Fit based upon off diagonal values = 1
## Measures of factor score adequacy
## ML1 ML2 ML3
## Correlation of (regression) scores with factors 1 1.00 0.96
## Multiple R square of scores with factors 1 0.99 0.91
## Minimum correlation of possible factor scores 1 0.99 0.83得到结果后,如何解读公共因子的含义呢?解释公因子\(F_i\)时,可以通过对载荷系数的绝对值较大的输入来解释,与主成分分析的R程序结果类似,这里同样需要注意,载荷系数的正负本身没有意义,但是不同载荷系数之间的正负对比是有意义的。以上面的结果为例,我们取公共因子的个数为3,3个公共因子反映的原始变量信息已占总信息的73%。查看输出的因子载荷矩阵A,以ML1对应的列(第一个公共因子的载荷向量)为例,除了投篮率、三分球技术指标、罚球率和盖帽次数外,其余各数值都接近或大于0.8,这表示其余的变量可以来解释公因子\(F_1\),或者说\(F_1\)主要反应这些变量的信息。观察第二个公共因子,其载荷没有0.8左右较大的值,虽然也可以根据相对大小按照以上想法解释,但是容易使公共因子的意义含糊不清,因此我们将介绍因子旋转后的因子载荷矩阵,其实际含义将更加明显。
正交旋转
当直接提取出的公共因子的典型代表变量不是非常突出时,容易使公共因子的实际意义含糊不清,不利于对因子进行解释,为此需要对因子载荷矩阵进行旋转变换,使得各因子载荷矩阵的每一列各元素的平方按列向0或1两极转化,达到其结构简化的目的。在NBA季后赛球员得分的案例中,我们使用正交旋转进一步提取因子,对新的结果进行解读。
## 因子旋转
fa <- fa(cor, n.obs = 2448, nfactors = 3, rotate = "varimax", fm = "ml")
fa## Factor Analysis using method = ml
## Call: fa(r = cor, nfactors = 3, n.obs = 2448, rotate = "varimax", fm = "ml")
## Standardized loadings (pattern matrix) based upon correlation matrix
## ML1 ML3 ML2 h2 u2 com
## 出场数 0.54 0.70 0.34 0.903 0.0970 2.4
## 上场总时间(min) 0.64 0.66 0.35 0.977 0.0228 2.5
## 投篮率 0.07 0.20 0.02 0.046 0.9537 1.2
## 命中次数 0.81 0.49 0.24 0.964 0.0359 1.9
## 出手次数 0.81 0.48 0.28 0.964 0.0365 1.9
## 三分投球率 -0.01 0.07 0.38 0.148 0.8521 1.1
## 三分命中次数 0.28 0.10 0.95 0.993 0.0074 1.2
## 三分出手次数 0.31 0.11 0.94 0.995 0.0048 1.2
## 罚球率 0.14 0.19 0.14 0.074 0.9258 2.8
## 罚球命中次数 0.92 0.33 0.20 0.993 0.0066 1.4
## 罚球出手次数 0.91 0.38 0.16 0.985 0.0154 1.4
## 篮板数 0.62 0.65 0.08 0.812 0.1879 2.0
## 助攻次数 0.67 0.41 0.34 0.729 0.2715 2.2
## 抢断次数 0.51 0.45 0.52 0.735 0.2650 3.0
## 盖帽次数 0.44 0.50 0.09 0.454 0.5462 2.0
## 失误次数 0.60 0.38 0.47 0.726 0.2738 2.6
## 犯规次数 0.61 0.69 0.23 0.902 0.0980 2.2
##
## ML1 ML3 ML2
## SS loadings 5.89 3.43 3.07
## Proportion Var 0.35 0.20 0.18
## Cumulative Var 0.35 0.55 0.73
## Proportion Explained 0.48 0.28 0.25
## Cumulative Proportion 0.48 0.75 1.00
##
## Mean item complexity = 1.9
## Test of the hypothesis that 3 factors are sufficient.
##
## The degrees of freedom for the null model are 136 and the objective function was 32.07 with Chi Square of 78273.06
## The degrees of freedom for the model are 88 and the objective function was 4.81
##
## The root mean square of the residuals (RMSR) is 0.04
## The df corrected root mean square of the residuals is 0.05
##
## The harmonic number of observations is 2448 with the empirical chi square 1017.8 with prob < 4.3e-158
## The total number of observations was 2448 with Likelihood Chi Square = 11717.56 with prob < 0
##
## Tucker Lewis Index of factoring reliability = 0.77
## RMSEA index = 0.232 and the 90 % confidence intervals are 0.229 0.236
## BIC = 11030.9
## Fit based upon off diagonal values = 1
## Measures of factor score adequacy
## ML1 ML3 ML2
## Correlation of (regression) scores with factors 0.99 0.96 1.00
## Multiple R square of scores with factors 0.98 0.93 1.00
## Minimum correlation of possible factor scores 0.96 0.86 0.99因子旋转后,第一个公共因子的因子载荷旋转后弱化了投篮率和三分投球率的意义,使得第一公因子主要解释了命中、出手次数和罚球的命中、出手次数,反映球员的比赛活跃与主动程度,可以称为场内活跃因子;第二个公共因子比旋转前加强了篮板数、盖帽次数、命中次数这几个变量的含义,因此可以更清晰地反映球员的技术水平因子;第三个公因子与旋转前相比,强化了三分命中次数和三分出手次数的解释,主要反映了三分球相关的信息,是球员对于整场球的胜算率加成因素。这和主成分分析得到的结论是类似的,由于因子分析结果进行了因子旋转,第二个和第三个公因子的共性方差相对大小发生了变化,因此公因子的顺序和旋转之前也略有区别。
计算因子得分
对fa()返回的对象使用factor.scores()函数,可以得到因子得分矩阵,通过这个得分,可以从几个公因子的角度对球员的综合实力进行评价。计算NBA数据的巴特莱特因子得分,设置参数method = 'Bartlett',查看得分矩阵的前六行。此外,在fa()函数返回的结果中,还可以得到得分系数(标准化的回归权重),储存在weights元素中。对于NBA数据集,输出对载荷矩阵进行旋转后得到的因子得分权重,并进行解读。
my_score <- factor.scores(nba[,2:18], fa, method="Bartlett")
head(my_score$scores)## ML1 ML3 ML2
## [1,] 12.579026 -4.495819 8.081668
## [2,] 11.992141 -3.365741 1.038594
## [3,] 6.600081 5.852415 -3.107882
## [4,] 9.424972 -2.345650 6.347182
## [5,] 9.883615 2.428957 -3.784769
## [6,] 8.289221 4.695544 -3.199542以第一个球员的因子得分为例,其在场内活跃度最高,三分球出手胜率加成也较好,但是命中率技术水平欠佳。
round(fa$weights,2) # 因子得分权重## ML1 ML3 ML2
## 出场数 -0.14 0.32 0.01
## 上场总时间(min) -0.43 1.09 0.02
## 投篮率 -0.01 0.01 0.00
## 命中次数 0.00 0.20 -0.02
## 出手次数 0.01 0.17 -0.02
## 三分投球率 0.00 0.01 0.00
## 三分命中次数 -0.05 -0.16 0.46
## 三分出手次数 -0.01 -0.31 0.66
## 罚球率 0.00 0.01 0.00
## 罚球命中次数 1.19 -1.16 -0.24
## 罚球出手次数 0.41 -0.29 -0.11
## 篮板数 -0.05 0.13 0.00
## 助攻次数 0.00 0.02 0.00
## 抢断次数 -0.02 0.06 0.01
## 盖帽次数 -0.01 0.04 0.00
## 失误次数 -0.01 0.02 0.00
## 犯规次数 -0.11 0.28 0.00根据因子得分权重的结果,每一个公共因子都可以表示为原变量的线性组合,由此得出因子得分函数。进一步地,把每个样本的观测值逐个代入因子得分函数后,即可得到样本的因子得分值。
因子分析结果可视化(选做)
若有2-3个公因子,还可以将每个样本的因子得分绘制在直角坐标系中,从而更清晰地看出样本的散布情况。这里以NBA数据为例,提取3个公因子,将2448个观测的因子得分散点图绘制在三维画布上如下所示。
## 3个公因子可视化因子得分
fa1 <- fa(cor, n.obs = 2448, nfactors = 3, rotate = "varimax", fm = "ml")
my_score <- factor.scores(nba[,2:18], fa1, method="Bartlett")
s <- data.frame(my_score$scores)## 绘制3D散点图(在命令行执行,用浏览器打开结果)
library(plotly)
library(magrittr)
plot_ly(x=s$ML1, # x axis
y=s$ML2, # y axis
z=s$ML3, # z axis
type = "scatter3d", size = 0.5) 习题答案
题目 8.1
R中自带的数据列表Harman23.cor包含了305个女孩的8个身体测量指标,列表的cov对象是原始数据及的相关系数矩阵。使用该相关系数矩阵,对8个身体指标进行主成分分析,用较少的变量替换这些原始的身体指标,并对结果进行解读。
library(psych)
my_cov <- Harman23.cor$cov## 主成分分析选择因子数目
par(family='STHeiti')
hw1 <- scree(my_cov, factors = F, pc = T, main = "主成分分析崖底碎石图", hline = -1)

## 提取主成分
pc <- principal(my_cov, nfactors = 2)
pc## Principal Components Analysis
## Call: principal(r = my_cov, nfactors = 2)
## Standardized loadings (pattern matrix) based upon correlation matrix
## RC1 RC2 h2 u2 com
## height 0.90 0.25 0.88 0.123 1.2
## arm.span 0.93 0.19 0.90 0.097 1.1
## forearm 0.92 0.16 0.87 0.128 1.1
## lower.leg 0.90 0.22 0.86 0.139 1.1
## weight 0.26 0.88 0.85 0.150 1.2
## bitro.diameter 0.19 0.84 0.74 0.261 1.1
## chest.girth 0.11 0.84 0.72 0.283 1.0
## chest.width 0.26 0.75 0.62 0.375 1.2
##
## RC1 RC2
## SS loadings 3.52 2.92
## Proportion Var 0.44 0.37
## Cumulative Var 0.44 0.81
## Proportion Explained 0.55 0.45
## Cumulative Proportion 0.55 1.00
##
## Mean item complexity = 1.1
## Test of the hypothesis that 2 components are sufficient.
##
## The root mean square of the residuals (RMSR) is 0.05
##
## Fit based upon off diagonal values = 0.99题目 8.2
R中自带的数据集USJudgeRatings包含了律师对美国高等法院法官的评分。数据框包含了43个观测、12个变量,变量表如下所示。
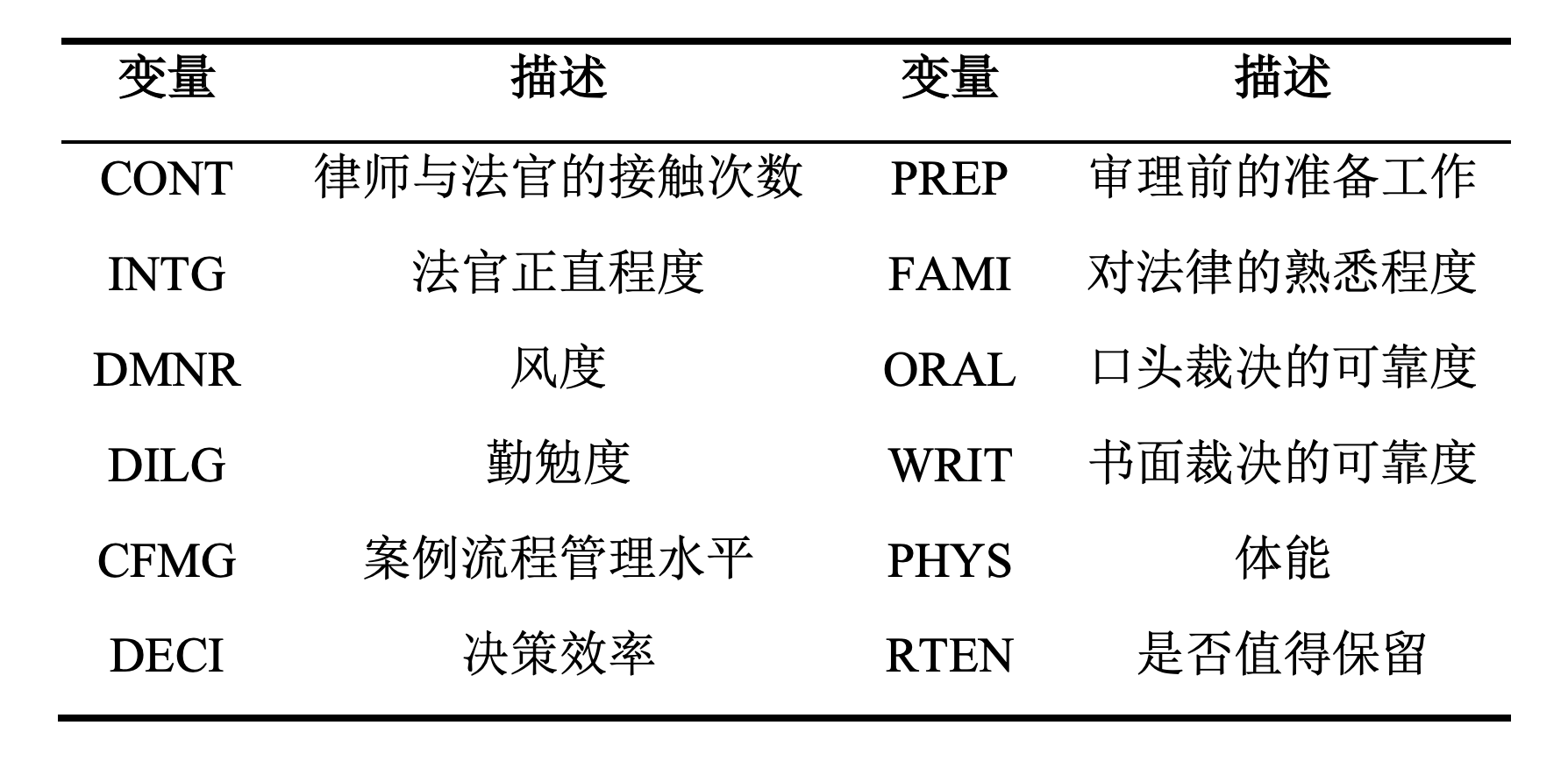 请使用主成分分析的方法,用较少的变量总结从
请使用主成分分析的方法,用较少的变量总结从INTG到RTEN这11个变量,使得这些主成分可以尽可能保留原始变量的信息,对结果进行解读,并计算43个观测样本的主成分得分。
USpredictor <- USJudgeRatings[, -1]## 主成分分析选择因子数目
par(family='STHeiti')
hw2 <- scree(USpredictor, factors = F, pc = T, main = "主成分分析崖底碎石图", hline = -1)

pc2 <- principal(USpredictor, nfactors = 1, scores = T)
pc2## Principal Components Analysis
## Call: principal(r = USpredictor, nfactors = 1, scores = T)
## Standardized loadings (pattern matrix) based upon correlation matrix
## PC1 h2 u2 com
## INTG 0.92 0.84 0.1565 1
## DMNR 0.91 0.83 0.1663 1
## DILG 0.97 0.94 0.0613 1
## CFMG 0.96 0.93 0.0720 1
## DECI 0.96 0.92 0.0763 1
## PREP 0.98 0.97 0.0299 1
## FAMI 0.98 0.95 0.0469 1
## ORAL 1.00 0.99 0.0091 1
## WRIT 0.99 0.98 0.0196 1
## PHYS 0.89 0.80 0.2013 1
## RTEN 0.99 0.97 0.0275 1
##
## PC1
## SS loadings 10.13
## Proportion Var 0.92
##
## Mean item complexity = 1
## Test of the hypothesis that 1 component is sufficient.
##
## The root mean square of the residuals (RMSR) is 0.04
## with the empirical chi square 6.21 with prob < 1
##
## Fit based upon off diagonal values = 1head(pc2$scores)## PC1
## AARONSON,L.H. -0.1857981
## ALEXANDER,J.M. 0.7469865
## ARMENTANO,A.J. 0.0704772
## BERDON,R.I. 1.1358765
## BRACKEN,J.J. -2.1586211
## BURNS,E.B. 0.7669406题目 8.3
R中自带的数据列表ability.cov提供了六个心理学测验的数据,包括112个参与者的观测值和6个变量:非语言的普通智力测验(general)、画图测验(picture)、积木图案测验(blocks)、迷宫测验(maze)、阅读测验(reading)和词汇测验(vocab),该列表的cov对象为变量间的协方差矩阵。使用因子分析的方法,选择合适的公因子数目,将6个变量转化为计较少的一组潜在心理学因素,解释不同公因子的含义。
cov_hw3 <- ability.cov$cov
corr <- cov2cor(cov_hw3)## 选择因子数目
par(family='STHeiti')
result2 <- scree(corr, factors = T, pc = F, main="因子分析崖底碎石图", hline = -1)

## 提取公共因子
fa_hw2 <- fa(corr, n.obs = ability.cov$n.obs, nfactors = 2, rotate = "none", fm = "ml")
fa_hw2## Factor Analysis using method = ml
## Call: fa(r = corr, nfactors = 2, n.obs = ability.cov$n.obs, rotate = "none",
## fm = "ml")
## Standardized loadings (pattern matrix) based upon correlation matrix
## ML1 ML2 h2 u2 com
## general 0.65 0.35 0.54 0.455 1.5
## picture 0.35 0.54 0.41 0.589 1.7
## blocks 0.47 0.75 0.78 0.218 1.7
## maze 0.25 0.41 0.23 0.769 1.7
## reading 0.96 -0.13 0.95 0.052 1.0
## vocab 0.82 -0.04 0.67 0.334 1.0
##
## ML1 ML2
## SS loadings 2.42 1.16
## Proportion Var 0.40 0.19
## Cumulative Var 0.40 0.60
## Proportion Explained 0.68 0.32
## Cumulative Proportion 0.68 1.00
##
## Mean item complexity = 1.4
## Test of the hypothesis that 2 factors are sufficient.
##
## The degrees of freedom for the null model are 15 and the objective function was 2.48 with Chi Square of 268.35
## The degrees of freedom for the model are 4 and the objective function was 0.06
##
## The root mean square of the residuals (RMSR) is 0.04
## The df corrected root mean square of the residuals is 0.07
##
## The harmonic number of observations is 112 with the empirical chi square 4.23 with prob < 0.38
## The total number of observations was 112 with Likelihood Chi Square = 6.11 with prob < 0.19
##
## Tucker Lewis Index of factoring reliability = 0.968
## RMSEA index = 0.068 and the 90 % confidence intervals are 0 0.171
## BIC = -12.77
## Fit based upon off diagonal values = 0.99
## Measures of factor score adequacy
## ML1 ML2
## Correlation of (regression) scores with factors 0.98 0.89
## Multiple R square of scores with factors 0.96 0.80
## Minimum correlation of possible factor scores 0.91 0.59## 因子旋转
farot_hw2 <- fa(corr, n.obs = ability.cov$n.obs, nfactors = 2, rotate = "varimax", fm = "ml")
farot_hw2## Factor Analysis using method = ml
## Call: fa(r = corr, nfactors = 2, n.obs = ability.cov$n.obs, rotate = "varimax",
## fm = "ml")
## Standardized loadings (pattern matrix) based upon correlation matrix
## ML1 ML2 h2 u2 com
## general 0.50 0.54 0.54 0.455 2.0
## picture 0.16 0.62 0.41 0.589 1.1
## blocks 0.21 0.86 0.78 0.218 1.1
## maze 0.11 0.47 0.23 0.769 1.1
## reading 0.96 0.18 0.95 0.052 1.1
## vocab 0.78 0.22 0.67 0.334 1.2
##
## ML1 ML2
## SS loadings 1.86 1.72
## Proportion Var 0.31 0.29
## Cumulative Var 0.31 0.60
## Proportion Explained 0.52 0.48
## Cumulative Proportion 0.52 1.00
##
## Mean item complexity = 1.3
## Test of the hypothesis that 2 factors are sufficient.
##
## The degrees of freedom for the null model are 15 and the objective function was 2.48 with Chi Square of 268.35
## The degrees of freedom for the model are 4 and the objective function was 0.06
##
## The root mean square of the residuals (RMSR) is 0.04
## The df corrected root mean square of the residuals is 0.07
##
## The harmonic number of observations is 112 with the empirical chi square 4.23 with prob < 0.38
## The total number of observations was 112 with Likelihood Chi Square = 6.11 with prob < 0.19
##
## Tucker Lewis Index of factoring reliability = 0.968
## RMSEA index = 0.068 and the 90 % confidence intervals are 0 0.171
## BIC = -12.77
## Fit based upon off diagonal values = 0.99
## Measures of factor score adequacy
## ML1 ML2
## Correlation of (regression) scores with factors 0.97 0.90
## Multiple R square of scores with factors 0.94 0.81
## Minimum correlation of possible factor scores 0.88 0.63